crawler 简单的爬取百度图片,并保存图片
正则匹配爬虫,json格式处理爬取百度图片
使用urlretrieve直接保存图片
Crawler 爬虫——爬取百度图片 简单的爬取网页图片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import urllibfrom urllib import request, parseimport reurl = "https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1600852001400_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E9%98%BF%E7%8B%B8" result = request.urlopen(url=url).read().decode('utf-8' ) rule = '"thumbURL":"(.*?)"' pic_list = re.findall(rule, result) a = 1 for i in pic_list: print (i) res = request.urlopen(i).read() string = str (a) + '.jpg' a = int (a)+1 with open (string, 'wb' ) as w: w.write(res)
正则匹配爬虫 百度图片搜索使用了ajax请求,所以找到Ajax请求的规律,就可以循环请求下载图片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from urllib import requestimport rea = 1 for pn in range (0 , 180 , 30 ): url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=6804522630827236065&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%98%BF%E7%8B%B8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E9%98%BF%E7%8B%B8&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30" .format (pn) result = request.urlopen(url).read().decode('utf-8' ) rule = 'middleURL":"(.*?)"' pic_list = re.findall(rule, result) for i in pic_list: print (i) res = request.urlopen(i).read() with open ("./img/" +str (a) + ".jpg" , 'wb' ) as w: w.write(res) a += 1
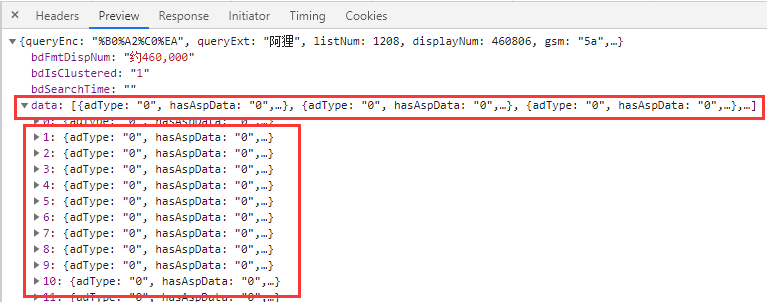
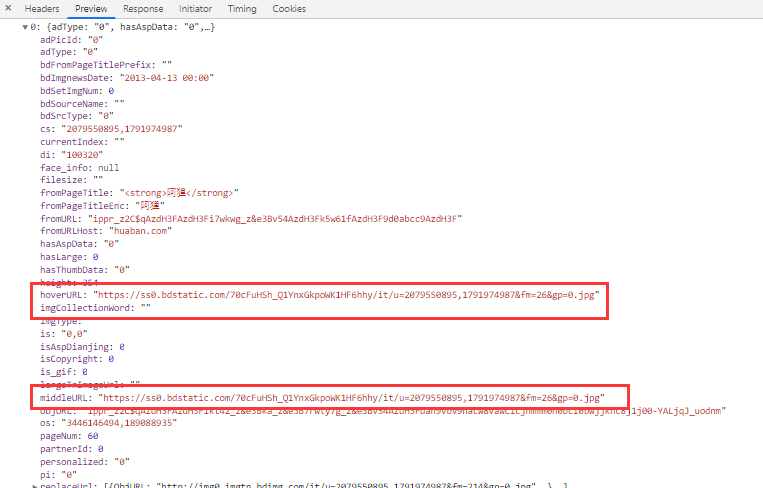
json格式处理爬取百度图片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from urllib import requestimport jsona = 1 for pn in range (0 , 180 , 30 ): url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=6804522630827236065&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%98%BF%E7%8B%B8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E9%98%BF%E7%8B%B8&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30" .format ( pn) result = request.urlopen(url).read().decode('utf-8' ) new_result = json.loads(result) print (new_result) for data in new_result['data' ]: img_url = data['middleURL' ] print (img_url) img_res = request.urlopen(img_url).read() with open ("./img/" + str (a) + ".jpg" , 'wb' ) as w: w.write(img_res) a += 1
使用urlretrieve直接保存图片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from urllib import requestimport jsonnum = 1 for page in range (0 , 120 , 30 ): url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=6804522630827236065&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%98%BF%E7%8B%B8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E9%98%BF%E7%8B%B8&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30" .format ( page) res = request.urlopen(url).read().decode("utf-8" ) for data in json.loads(res)['data' ]: if data: img_url = data['thumbURL' ] request.urlretrieve(img_url, filename="./img/" + str (num) + ".jpg" ) num += 1